Announcing vLLM-Omni: Easy, Fast, and Cheap Omni-Modality Model Serving
We are excited to announce the official release of vLLM-Omni, a major extension of the vLLM ecosystem designed to support the next generation of AI: omni-modality models.
![]()
Since its inception, vLLM has focused on high-throughput, memory-efficient serving for Large Language Models (LLMs). However, the landscape of generative AI is shifting rapidly. Models are no longer just about text-in, text-out. Today’s state-of-the-art models reason across text, images, audio, and video, and they generate heterogeneous outputs using diverse architectures.
vLLM-Omni is an open source framework to support omni-modality model serving that extends vLLM’s exceptional performance to the world of multi-modal and non-autoregressive inference.
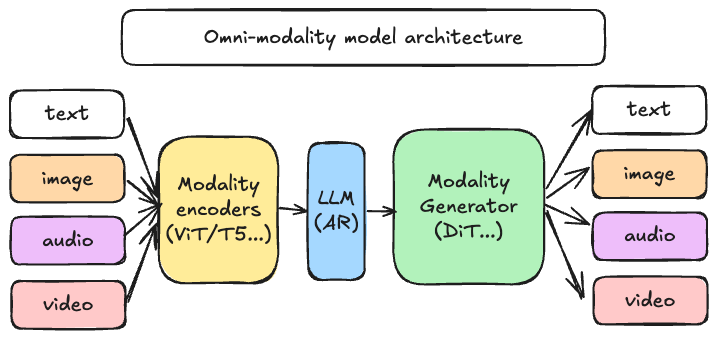
Why vLLM-Omni?
Traditional serving engines were optimized for text-based Autoregressive (AR) tasks. As models evolve into “omni” agents—capable of seeing, hearing, and speaking—the serving infrastructure must evolve with them.
vLLM-Omni addresses three critical shifts in model architecture:
- True Omni-Modality: Processing and generating Text, Image, Video, and Audio seamlessly.
- Beyond Autoregression: Extending vLLM’s efficient memory management to Diffusion Transformers (DiT) and other parallel generation models.
- Heterogeneous Model Pipeline: Orchestrating complex model workflows where a single request can invoke multiple heterogeneous model components. (e.g, multimodal encoding, AR reasoning, diffusion-based multimodal generation, etc).
Inside the Architecture
vLLM-Omni is not just a wrapper; it is a re-imagining of how vLLM handles data flow. It introduces a fully disaggregated pipeline that allows for dynamic resource allocation across different stages of generation. As shown above, the architecture unifies distinct phases:
- Modality Encoders: Efficiently encoding multimodal inputs (ViT, Whisper, etc.)
- LLM Core: leveraging vLLM’s PagedAttention for the autoregressive reasoning stage.
- Modality Generators: High-performance serving for DiT and other decoding heads to produce rich media outputs.
Key Features
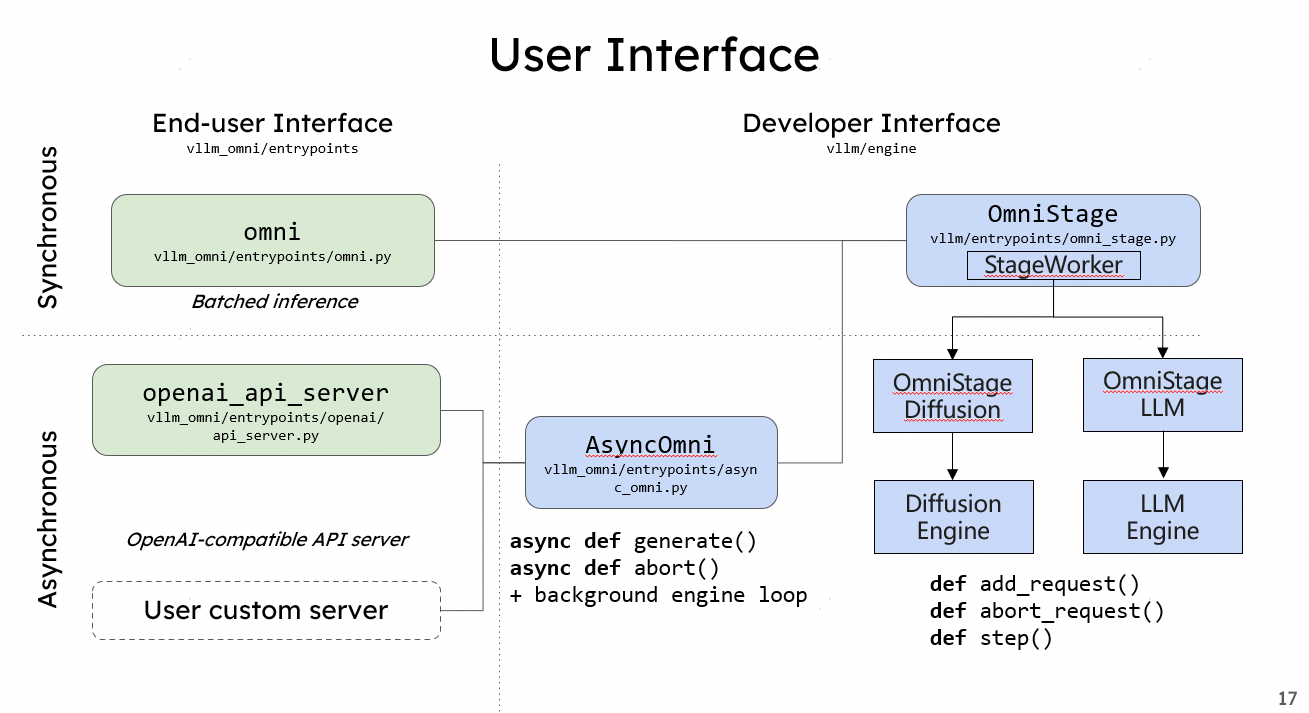
-
Simplicity: If you know how to use vLLM, you know how to use vLLM-Omni. We maintain seamless integration with Hugging Face models and offer an OpenAI-compatible API server.
-
Flexibility: With the OmniStage abstraction, we provide a simple and straightforward way to support various omni-modality models including Qwen-Omni, Qwen-Image, and other state-of-the-art models.
-
Performance: We utilize pipelined stage execution to overlap computation for high throughput performance, ensuring that while one stage is processing, others aren’t idle.
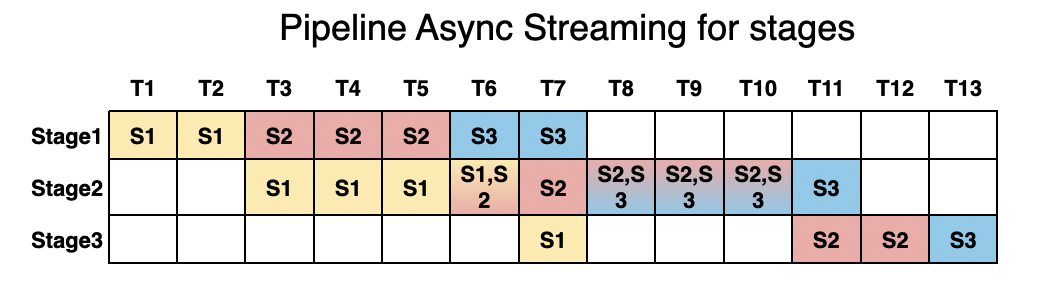
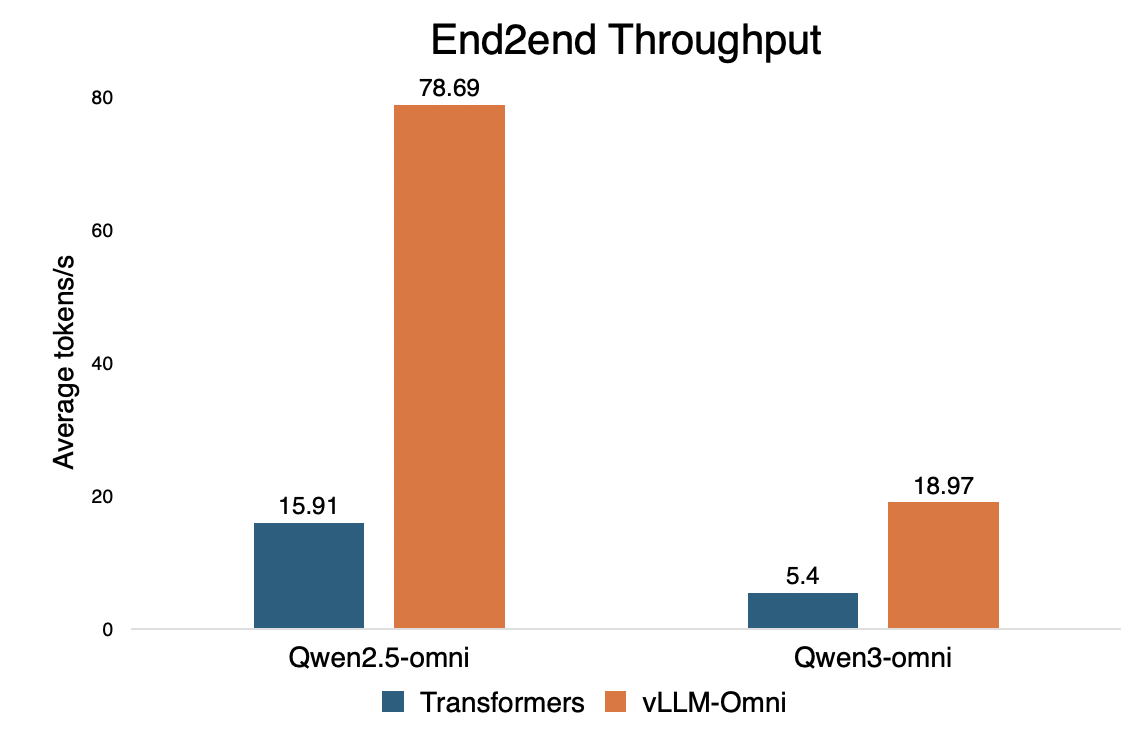
We benchmarked vLLM-Omni against Hugging Face Transformers to demonstrate the efficiency gains in omni-modal serving.
Future Roadmap
vLLM-Omni is evolving rapidly. Our roadmap is focused on expanding model support and pushing the boundaries of efficient inference even further.
- Expanded Model Support: We plan to support a wider range of open-source omni-models and diffusion transformers as they emerge.
- Deeper vLLM Integration: merging core omni-features upstream to make multi-modality a first-class citizen in the entire vLLM ecosystem.
- Diffusion Acceleration: parallel inference(DP/TP/SP/USP…), cache acceleration(TeaCache/DBCache…) and compute acceleration(quantization/sparse attn…).
- Full disaggregation: Based on the OmniStage abstraction, we expect to support full disaggregation (encoder/prefill/decode/generation) across different inference stages in order to improve throughput and reduce latency.
- Hardware Support: Following the hardware plugin system, we plan to expand our support for various hardware backends to ensure vLLM-Omni runs efficiently everywhere.
Getting Started
Getting started with vLLM-Omni is straightforward. The initial vllm-omni v0.11.0rc release is built on top of vLLM v0.11.0.
Installation
Check out our Installation Doc for details.
Serving the omni-modality models
Check out our examples directory for specific scripts to launch image, audio, and video generation workflows. vLLM-Omni also provides the gradio support to improve user experience, below is a demo example for serving Qwen-Image:
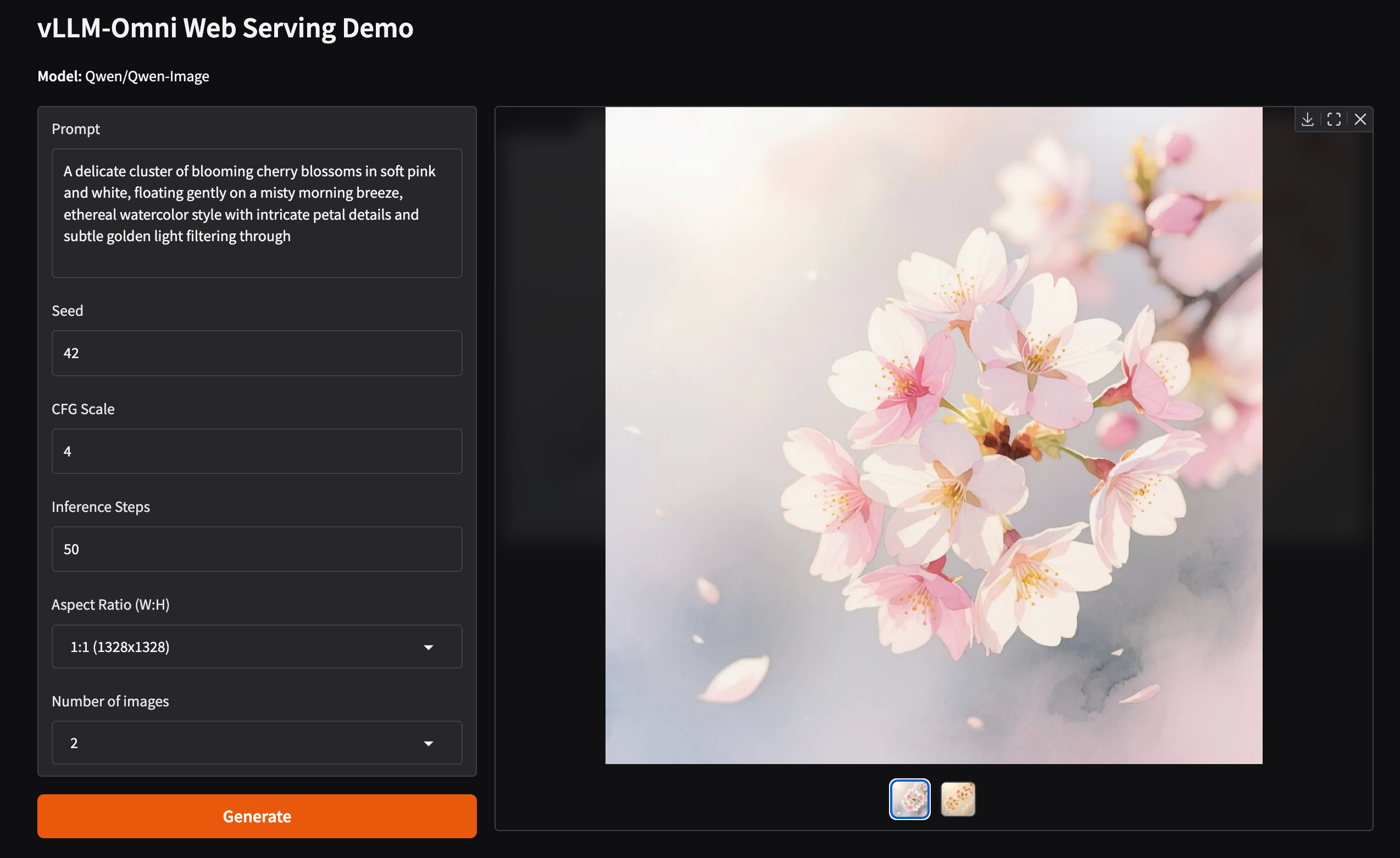
Join the Community
This is just the beginning for omni-modality serving. We are actively developing support for more architectures and invite the community to help shape the future of vLLM-Omni.
-
Code & Docs: GitHub Repository Documentation - Weekly Meeting: Join us every Wednesday at 11:30 (UTC+8) to discuss roadmap and features. Join here.
Let’s build the future of omni-modal serving together!